
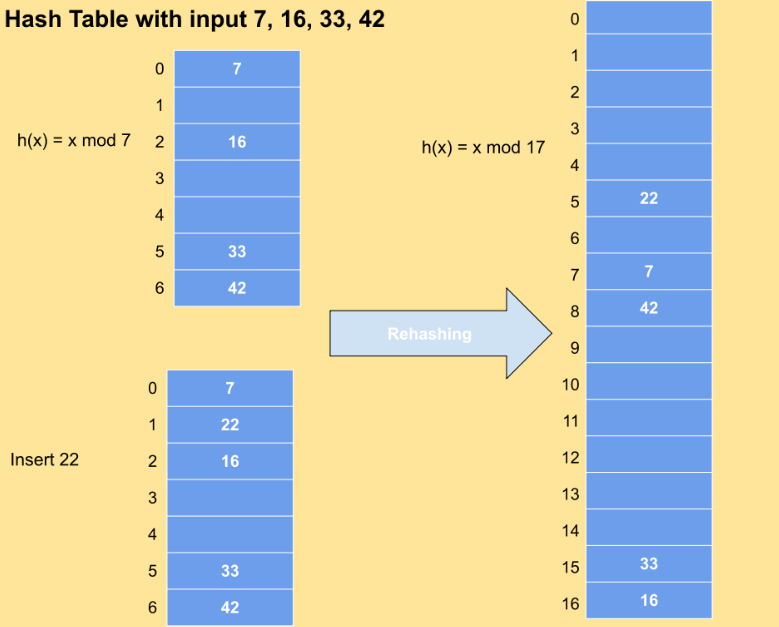
📌 - Rehash()
해쉬 테이블의 버킷 용량이 증가하면 모든 항목을 더 큰 크기의 해쉬맵으로 균등하게 분배하는 작업
HashMap의 버킷을 두배로 늘리고 안의 요소들을 전부 재배치 하는 작업
size_t old_bucket_cnt, new_bucket_cnt;
struct list *new_buckets, *old_buckets;- old_bucket_cnt, new_bucket_cnt와, new_buckets, old_buckets를 초기화
old_buckets = h->buckets;
old_bucket_cnt = h->bucket_cnt;- old_buckets와 old_bucket_cnt를 이전 값으로 설정
new_bucket_cnt = h->elem_cnt / BEST_ELEMS_PER_BUCKET;- 새로운 버킷의 갯수를 현재 해쉬 요소의 갯수 / 2 로 설정
if (new_bucket_cnt < 4)
new_bucket_cnt = 4;
while (!is_power_of_2 (new_bucket_cnt))
new_bucket_cnt = turn_off_least_1bit (new_bucket_cnt);- 여기서는 만약 새로운 버킷의 개수가 4개이하면 충돌, 효율을 위해 새로운 버컷의 개수를 4개로 초기화
- is_power_of_2 함수는 new_bucket_cnt가 2의 거듭제곱인지 확인
- 2의 거듭제곱이 아니라면 비트 연산자로 가장 오른쪽의 1을 0으로 바꿔주면서 거듭제곱 형태로 바꿔줌
- ex ) 1110이면 1000으로 만들어서 2의 거듭제곱으로 만들어줌
if (new_bucket_cnt == old_bucket_cnt)
return;- 현재 버킷의 개수와 이전 버킷의 개수가 같다면 재배치를 하지 않고 종료
new_buckets = malloc (sizeof *new_buckets * new_bucket_cnt);
if (new_buckets == NULL) {
/* Allocation failed. This means that use of the hash table will
be less efficient. However, it is still usable, so
there's no reason for it to be an error. */
return;
}- 새로운 버킷을 new_bucket_cnt의 개수로 초기화
- 만약 new_buckets가 NULL이면 종료
이후 아래의 코드는 new_bucket_cnt가 2의 거듭제곱이면서 이전의 버킷개수(old_bucket_cnt)와 다르면 재배치를 해주는 코드임
pintos의 rehash는 insert, delete, replace를 할때마다 사용하게 되는데, 물론 new_bucket_cnt와 old_bucket_cnt가 같으면 재배치를 해주지 않지만 rehash를 일단 실행하는 것 자체가 비효율적이라는 생각이 들어서 아래의 주석처럼 LOAD_FACTOR를 사용해서 rehash를 진행 시켜주면 더 효율적이지 않을까라는 생각이 듬
struct hash_elem *
hash_insert (struct hash *h, struct hash_elem *new) {
struct list *bucket = find_bucket (h, new);
struct hash_elem *old = find_elem (h, bucket, new);
if (old == NULL)
insert_elem (h, bucket, new);
rehash (h);
// if (h->elem_cnt >= h->bucket_cnt * LOAD_FACTOR){
// rehash (h);
// }
return old;
}
🔥- 전체 코드
static void
rehash (struct hash *h) {
size_t old_bucket_cnt, new_bucket_cnt;
struct list *new_buckets, *old_buckets;
size_t i;
ASSERT (h != NULL);
/* Save old bucket info for later use. */
old_buckets = h->buckets;
old_bucket_cnt = h->bucket_cnt;
/* Calculate the number of buckets to use now.
We want one bucket for about every BEST_ELEMS_PER_BUCKET.
We must have at least four buckets, and the number of
buckets must be a power of 2. */
new_bucket_cnt = h->elem_cnt / BEST_ELEMS_PER_BUCKET;
if (new_bucket_cnt < 4)
new_bucket_cnt = 4;
while (!is_power_of_2 (new_bucket_cnt))
new_bucket_cnt = turn_off_least_1bit (new_bucket_cnt);
/* Don't do anything if the bucket count wouldn't change. */
if (new_bucket_cnt == old_bucket_cnt)
return;
/* Allocate new buckets and initialize them as empty. */
new_buckets = malloc (sizeof *new_buckets * new_bucket_cnt);
if (new_buckets == NULL) {
/* Allocation failed. This means that use of the hash table will
be less efficient. However, it is still usable, so
there's no reason for it to be an error. */
return;
}
for (i = 0; i < new_bucket_cnt; i++)
list_init (&new_buckets[i]);
/* Install new bucket info. */
h->buckets = new_buckets;
h->bucket_cnt = new_bucket_cnt;
/* Move each old element into the appropriate new bucket. */
for (i = 0; i < old_bucket_cnt; i++) {
struct list *old_bucket;
struct list_elem *elem, *next;
old_bucket = &old_buckets[i];
for (elem = list_begin (old_bucket);
elem != list_end (old_bucket); elem = next) {
struct list *new_bucket
= find_bucket (h, list_elem_to_hash_elem (elem));
next = list_next (elem);
list_remove (elem);
list_push_front (new_bucket, elem);
}
}
free (old_buckets);
}